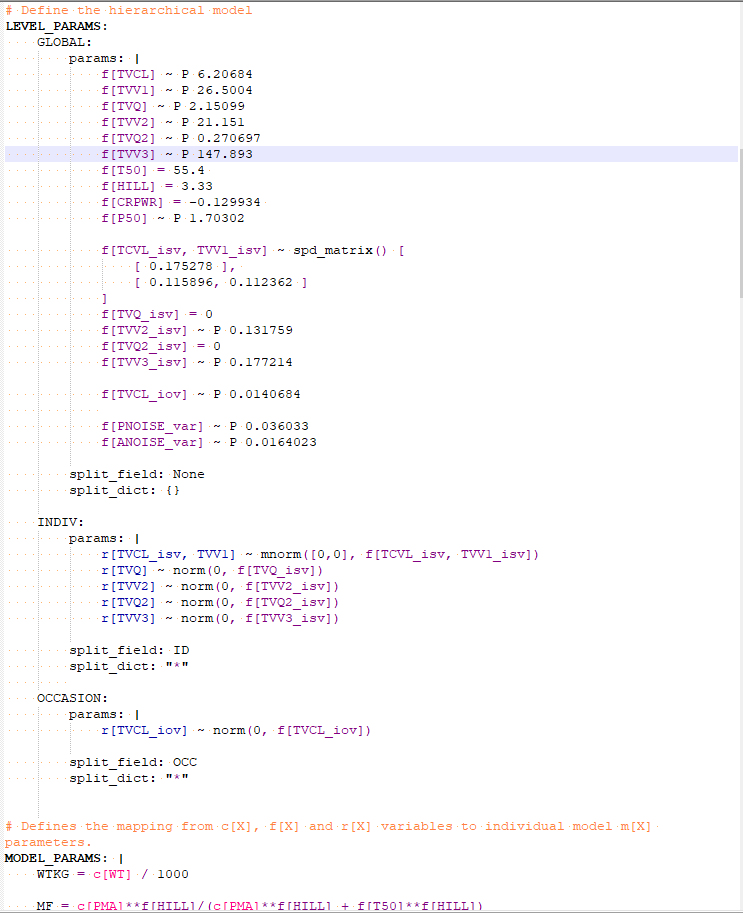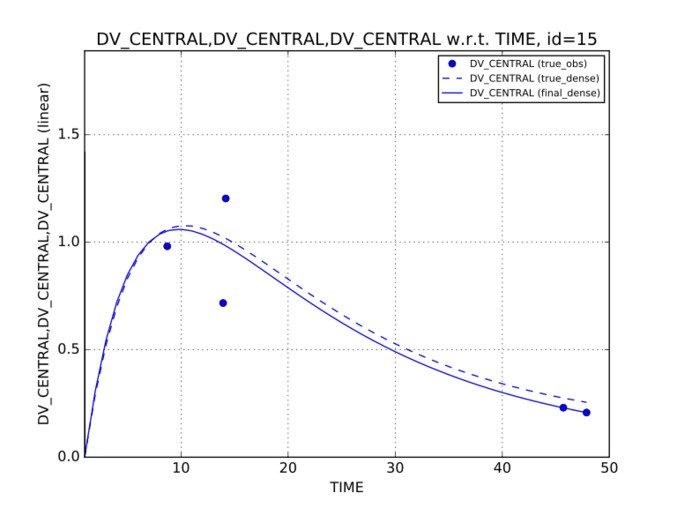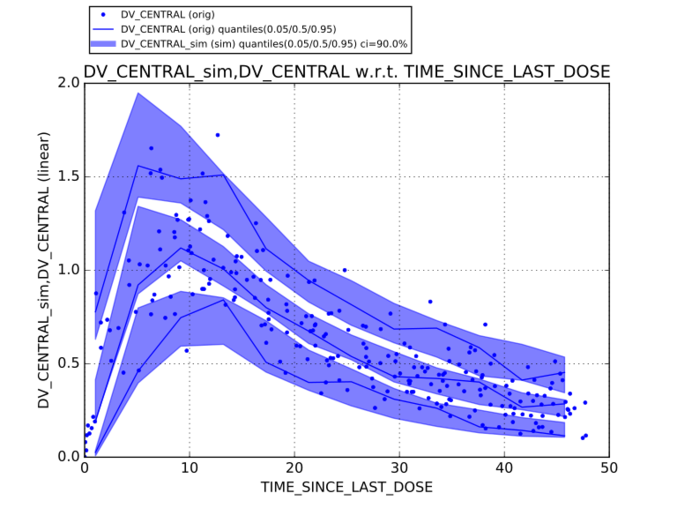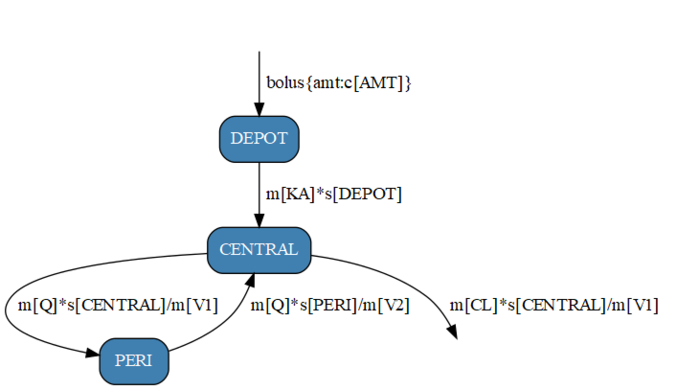
PoPy is a suite of powerful, robust software tools, written in Python, for population modelling of pharmacokinetic/pharmacodynamic (PK/PD) data.
For decades, mathematical modelling for PK/PD has been dominated by NONMEM – a massive breakthrough for the field in the 1970s. (Some of the original FORTRAN code, written by Stuart Beale, is still in use today!) Although alternative modelling packages exist they often differ in their interface and algorithm choices, making it difficult for users to make the transition and introducing uncertainty about the results.
When we conceived PoPy, we wanted it to have properties that bridge this gap: powerful modelling that uses robust, deterministic algorithms and an easy-to-use interface that can be explained in terms of software most users are familiar with, all written in a modern language that makes the package easy to maintain and extend as new methods and tools are invented.
Free for Academic and Educational Use
Because we believe in the value of PK/PD modelling, we think the tools to learn the necessary skills should be as widely available as possible. That is why, from day one, a version of PoPy will be available under a licence that is free for academic and educational use. With PoPy, students can learn about population modelling using a language that is transparent, elegant, explicit, and free of the idiosyncracies of legacy software packages.